- 21. August 2019
- 53 Min
JavaScript SEO Guide
Crawling, Indexierung und Auditing von JavaScript-Webseiten
- Können Suchmaschinen JavaScript-Webseiten crawlen und indexieren?
- Technologien von Crawlern – Wie interagiert ein Crawler mit JavaScript?
- Wie wird JavaScript ausgeführt?
- Quellcode vor und nach dem Rendern
- Headless-Browser – Wie interagiert ein Crawler mit einer Webseite?
- Googlebot Rendering – Welche Technologien nutzt der Googlebot um Webseiten zu rendern?
- Google Caffeine (Indexer) ist für das Rendering zuständig
- Rendering von JavaScript vs. HTML
- Umgang unterschiedlicher Suchmaschinen mit Javascript – Google ist nicht alles!
- Bing JavaScript SEO – Kann Bing JavaScript?
- CRAWLING UND INDEXIERUNG VON VERSCHIEDENEN JAVASCRIPT-FRAMEWORKS
- JavaScript rendering ist ressourcenintensiv
- Zusammenfassung – Crawler-Interaktion mit JavaScript
- SEO-Auditing-Tools für JavaScript-Webseiten
- Developer Tools des Google Chrome Browsers
- Auditing vom gerenderten QUellcode mit den Chrome Developer Tools
- Google Search Console – URL-Prüfungs-Tool
- Site-Abfrage in der Google-Suche – Google Index überprüfen
- Google Mobile Friendly Tester – Von Google gerenderter Code
- Screaming Frog SEO Spider
- Ryte Bussines Suite – Vorstellung inkl. Intervie mit Marcus Tandler
- Searchmetrics Suite – Vorstellung inkl. Interview mit Malte Landwehr
- Zusammenfassung– SEO-Auditing-Tools für JavaScript Webseiten
- Best Practice Empfehlungen von Google zu JavaScript SEO
- UMGANG MIT DYNAMISCHEN INHALTEN
- Die 5 Sekunden-Regel – Googlebot ist ungeduldig
- Indexierbare URLs – Darauf sollte bei Verlinkungen geachtet werden
- Einsatz von Canonical-Tags
- Lösungen für den Head-Bereich
- Lazy Loading von Bildern für JavaScript-Webseiten
- Wie geht Google mit dem Ajax Schema um?
- Zusammenfassung – Best Practices im SEO für JavaScript-Webseiten
- Serverseitiges Rendering von JavaScript – Prerendering
- Berücksichtigung von anderen Suchmaschinen?
- Wie funktioniert Prerendering?
- Einfaches Testing von Prerendering für SEOS
- DYNAMIC RENDERING – GOOGLE EMPFIEHLT DEN EINSATZ VON PRERENDERING
- Prerendering – Eigene Lösungen oder kostenpflichtige Dienste?
- Nachteile von Prerendering – Worauf besonders achten?
- Isomorphic (universal) JavaScript– Die ultimative Lösung für JavaScript SEO?
- Zusammenfassung– Prerendering (Server-Side-Rendering) für JavaScript-Webseiten
- Gedanken zu JavaScript SEO – Wie sieht die Zukunft von JavaScript SEO aus?
- Welche Punkte erschweren SEO-Verantwortlichen den Umgang mit JavaScript?
- Ist JavaScript für SEO zu empfehlen?
- Vorträge über JavaScript SEO
- Searchmetrics Webinar-Aufzeichnung 2018 – JavaScript SEO
- SEO Day 2018 Slides – JavaScript SEO
- SEO CAMPIXX 2018 Slides – JavaScript SEO
- SEOKOMM 2017 Slides – JavaScript SEO

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Laut offiziellen Aussagen Seitens Google kann der Googlebot JavaScript rendern, die Inhalte crawlen und indexieren. Google bestätigt immer wieder, dass der Suchmaschinen-Konzern ein gutes Verständnis dafür hat JavaScript zu rendern und die dadurch erzeugten Inhalte zu crawlen.
Leider gibt es einige Fallstudien die genau diese Aussage wiederlegen. Liegt es bei diesen Fallstudien wirklich an der mangelnden Interpretationsfähigkeit Seitens Googles oder schlichtweg an einer fehlerhaften Implementierung von JavaScript? JavaScript ist weit aus komplexer für Crawler als reines HTML. Wieso man sich auf sehr dünnes Eis begibt, wenn man JavaScript Client-Side ausspielt, wird in diesem Beitrag im Detail beleuchtet.
Abgesehen davon gibt es zum aktuellen Stand wenige Crawler die JavaScript rendern können. Crawler von anderen Suchmaschinen und sozialen Netzwerken versuchen überhaupt nicht JavaScript zu rendern und das aus einem guten Grund. Auch führende SEO-Tools sind hinsichtlich dieser Thematik noch hinterher. Wieso neben Google nur wenige JavaScript rendern und wieso sich das wohl in naher Zukunft nicht ändert, wird in diesem Beitrag erklärt.
Um als SEO-Verantwortlicher mit JavaScript umgehen zu können, sollten ein paar wichtige JavaScript-Grundlagen und die Technologien von Crawlern bekannt sein, um die gesamte Problematik zu verstehen und sich der Risiken bewusst zu sein.

Zu Beginn einige Grundlagen, um das Thema in den nächsten Absätzen zu verdeutlichen. Hier einer der größten Unterschiede und gleichzeitig der Hauptgrund wieso JavaScript für Crawler eine Herausforderung darstellt. JavaScript wird nicht vom Server, sondern vom Browser (Client) ausgeführt. Ein vereinfachter Ablauf wird im Folgenden erläutert und ist in Abbildung 1 grafisch dargestellt:
- 1.Der Browser stellt eine GET-Anfrage an den Server
- 2.Der Server führt das PHP-Script aus (z.B. beim Einsatz eines CMS)
- 3.Der Server gibt den HTML-Quellcode an den Browser zurück
- 4.Der Browser führt das JavaScript aus
Bei einer Webseite ohne Einsatz von JavaScript liegt bereits nach Punkt 3 der Inhalt einer Webseite dem Browser oder einem Crawler vor. JavaScript-Code wird erst in Punkt 4 vom Browser selbst ausgeführt.
Genau hier liegt das große Problem. Damit ein Crawler Inhalte die durch JavaScript ausgeführt werden crawlen kann, muss dieser die Arbeit eines Browsers übernehmen inklusive aller nötigen Technologien und Ressourcen, wie z.B. einer Rendering-Engine. Auch Tools die beim Auditing unterstützend helfen, müssen über diese Technologien verfügen um valide Daten zu liefern.
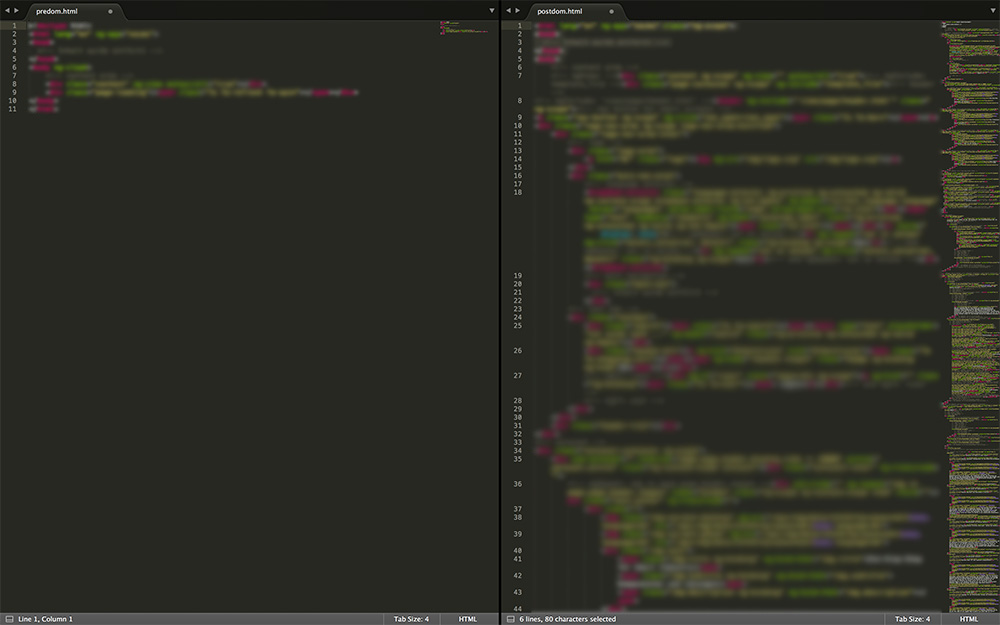
Mit einem Blick auf den Quellcode einer JavaScript-Basierenden Webseite, wird schnell deutlich, dass die vom Browser angezeigten Inhalte im Quellcode nicht zu sehen sind. Das liegt daran, dass kein JavaScript ausgeführt wurde, also der DOM der Webseite nicht gerendert wurde. Erst nachdem JavaScript ausgeführt wird, werden alle Inhalte auch im Quellcode sichtbar.
In der linken Spalte in Abbildung 2 ist der Quellcode einer JavaScript-Basierenden Webseite zu sehen. Hier ist gut zu erkennen, dass im Quellcode keinerlei Inhalte zu sehen sind. In der rechten Spalte wurde JavaScript bereits ausgeführt, daher sind hier alle Inhalte die im Browser zu sehen sind auch im Body-Bereich des gerenderten Quellcodes vorhanden.
Um vereinfacht darzustellen, wie ein Crawler mit einer Webseite interagiert, wird der Crawler wie einen Headless-Browser betrachtet.
Ein Headless-Browser beschreibt relativ genau, wie der Googlebot mit einer JavaScript-Basierenden Webseite interagiert, deswegen ist es hilfreich zu verstehen, wie ein Headless-Browser arbeitet.
Ein Headless-Browser ist ein Browser ohne visuelle Komponenten. Das bedeutet, dass ein Headless-Browser keine Inhalte darstellt um mit diesen wie ein Webseitenbesucher zu interagieren. Dieser interagiert mittels Befehlen mit einer Webseite.
Um die Arbeitsweise eines Headless-Browser einfacher zu verdeutlichen, wurde der Headless-Mode des Google Chrome Browser genutzt. Der Headless-Mode ist seit der Version 59 für Mac OS und Linux und seit der Version 61 für Windows verfügbar. Laut Spekulationen wurde der Headless Chrome für den Googebot entwickelt.
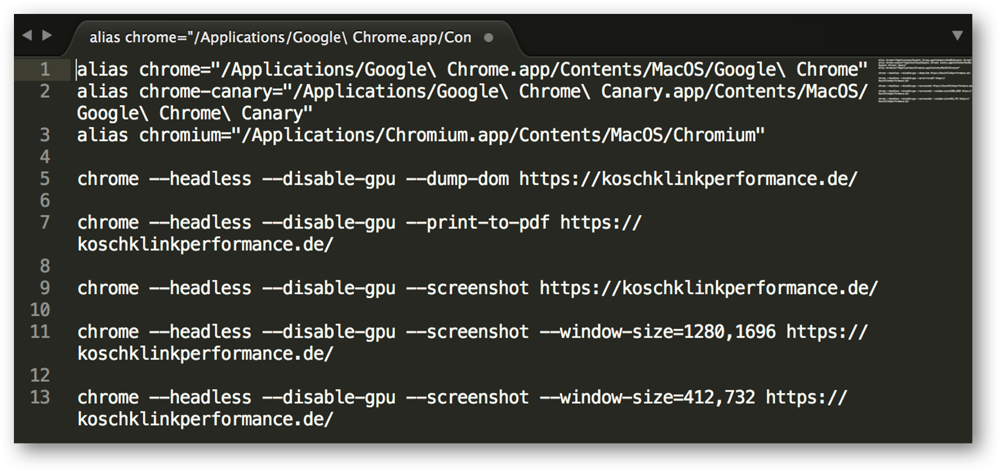
Um den Headless Chrome (Headless Mode von Google Chrome) nutzen zu können, genügt die Konsole bei Windows bzw. das Terminal bei Mac OS. In Abbildung 3 sind einfache Befehle verwendet worden, um den Headless Chrome zu steuern.
In Zeile 1 wurde lediglich der Pfad der Installation von Google Chrome hinterlegt um mit dem Befehl „chrome“ direkt auf den Browser zugreifen zu können. Zeile 5 kann folgend interpretiert werden:
- Chome: Zugriff auf den Google Chrome Browser
- –headless: Google Chrome im Headless-Mode ausführen
- –disable-gpu: Dieser Befehl ist laut Google aktuell nur wegen eines Problems notwendig
- –dump-dom: Ausgeben des DOM
- Url: Diese Url wird für den Befehl angesteuert
Nach der Eingabe dieser Befehle liest der Headless Chrome den DOM der angegebenen Webseite aus und gibt diesen direkt in der Konsole bzw. Terminal aus. Der DOM kann danach beliebig in ein Textprogramm eingefügt und analysiert werden.
Zur Verdeutlichung wurden noch weitere Befehle ausgeführt. In Zeile 8 wird der Headless Chrome die angegebene Webseite als PDF speichern. Ab Zeile 9 wird von der Webseite ein Screenshot der Webseite, je nach Wahl der Pixel-Größe, erstellen und gespeichern.
Vereinfacht sollen dieses Befehle verdeutlichen, wie ein Crawler sich durch die Webseite arbeitet.
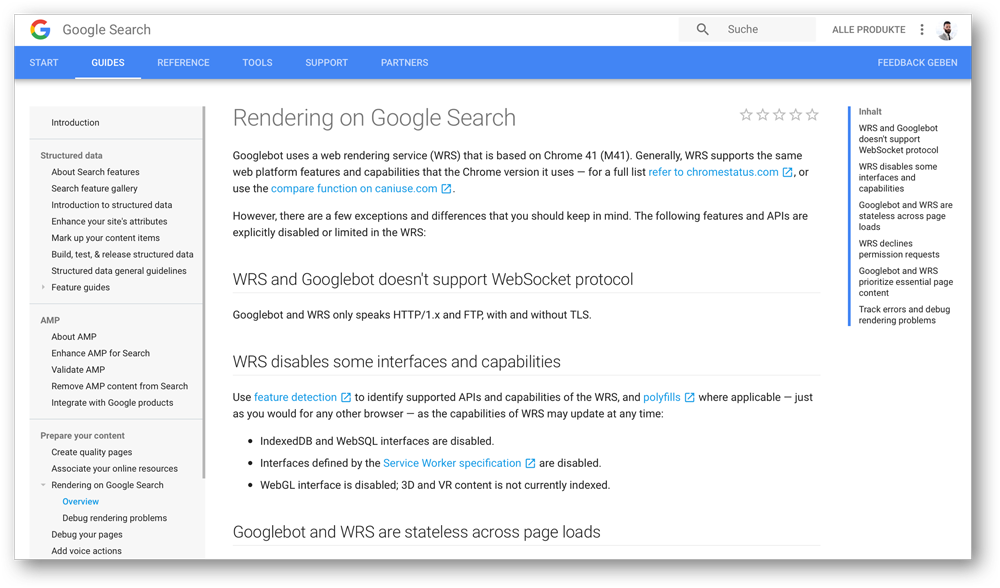
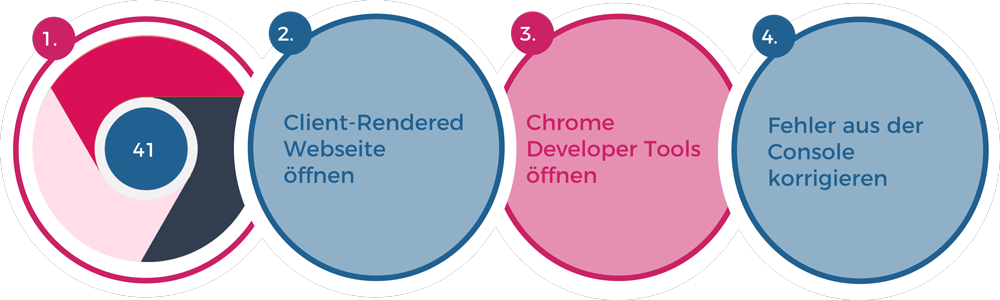
Erst im August 2017 wurden von Google tiefere Einblicke in die Technologie beim Rendern von Webseiten des Googlebots veröffentlicht. Bis Dato war über das Rendering des Googlebots kaum etwas bekannt und lediglich die Google Search Console diente als valide Quelle für Debugging und Testing.
Laut diesem Dokument nutzte der Googlebot den Web Rendering Service (WRS) welcher auf dem Google Chrome 41 basiert, um Webseiten zu rendern. Diese Version (Download Chrome Version 41) des Google Chrome Browsers stammt aus dem Jahr 2015 und verfügt etwa über 60% der Technologien und Features der aktuellen Chrome Version. Wer sich selbst ein Bild machen möchte, welche Unterschiede zwischen Version 41 und der aktuellen Chrome-Version sind erfährt alle Feature-Unterschiede im Detail auf Caniuse.com und Chrome Platform Status deutlich.
Knapp zwei Jahre nach Publikation dieses Dokumentes veröffentliche Google, dass der Googlebot nun endlich „evergreen“ läuft. Das bedeutet, dass der Googlebot sich immer an die Features und Funktionen der aktuellen Version des Chrome Browsers anpasst. Der geschätzte Kollege Valentin Pletzer hat hierfür eine Webseite eingerichtet, die beim Besuch vom Googlebot dessen Version testet, um zu verifizieren, ob nach einer Aktualisierung des Chromes, der Googlebot auch die neuen Features unterstützt. Da Google laut eigenen Aussagen den User-Agent nicht ändern wird, wird der Google Bot immer als Chrome 41 identifiziert. Dies hat aber nichts mit der Version des WRS des Googlebots zu tun.
Des Weiteren ist bekannt, dass der Googlebot das Transfer Protokoll HTTP/2 aktuell nicht unterstützt. Da HTTP/2 Abwärtskompatibel ist, sollte dies keine Probleme darstellen. Zudem gibt es keine Unterstützung für WebSocket-Protokoll, IndexedDB und WebSQL-Interfaces zur Datenhaltung im Browser. Inhalte die erst nach Zustimmung des Users angezeigt werden, werden ebenfalls nicht indexiert. Interessant ist auch die Information, dass Inhalte des Local Storages sowie Session Storages gelöscht werden und beim Aufruf einer neuen Url HTTP-Cookies gelöscht werden.
Weitere Guides direkt vom Google zum Thema Rendering und JavaScript gibt es auf der Google Developers Webseite.
Vermehrt herrscht die Meinung, dass der Crawler, bei Google ist es der Googlebot, für das Rendern von JavaScript verantwortlich ist. Dies ist aber ein Fehlglaube. Das Rendern von JavaScript übernimmt erst der Indexer, bei Google ist es Caffeine. Genauer gesagt, ist es der Web Rendering Service (WRS), der ein Teil von Caffeine ist. Genauso wie der PageRanker ein Teil von Caffeine ist. Mehr zu den Technologien die Google für das Rendern von JavaScript nutzt, werden weiter im Artikel erläutert.

Um sich über die Herausforderungen, vor denen Suchmaschinen beim Crawlen und Indexieren von JavaScript-Inhalten stehen, bewusst zu sein, ist es wichtig zu verstehen, wie der Ablauf einer Suchmaschine beim Crawlen und Indexieren von Html-Webseiten im Vergleich zu JavaScript-Webseiten aussieht. Der folgende Ablauf dient als vereinfachte Darstellung.
Ablauf beim Crawlen von Html-Inhalten
- 1.HTML-Dateien werden runtergeladen
- 2.Links werden aus dem Quellcode entnommen und können gecrawlt werden
- 3.CSS-Dateien werden runtergeladen
- 4.Googlebot (Crawler) sendet alle Ressourcen zu Caffeine (Indexer)
- 5.Googlebot sendet alle Ressourcen zu Caffeine
Dieser Prozess kann einem Ablauf abgeschlossen werden. Das bedeutet, nach dem der Crawler seine Schritte absolviert hat, werden die weiteren Arbeitsabläufe an den Indexer übergeben. Wenn dieser fertig ist, ist der Ablauf abgeschlossen bis der Crawler die Webseite erneut besucht.
Ablauf beim Crawlen von JavaScript-Inhalten
- 1.HTML-Dateien werden runtergeladen
- 2.CSS- und JavaScript-Daten werden parallel runterladen
- 3.WRS (Web Rendering Service) wird genutzt (Teil von Caffeine) um JS auszuführen
- 4.WRS rendert alle Dateien
- 5.Caffeine kann nun die Inhalte ggf. indexieren
- 6.Erst jetzt kann Googlebot neue Links crawlen
Der große Nachteil bei diesem Ablauf ist, dass dieser für jede einzelne Url wiederholt werden muss, da der Indexer erst JavaScript rendern muss, um an die weiteren links zu kommen, die der Crawler dann besuchen kann. Hier entsteht für die Suchmaschinen also nicht nur der Aufwand des Rendern von JavaScript, sondern auch beim Crawlen ist der Prozess sehr umständlich.
Ablauf beim Crawlen von JavaScript-Inhalten
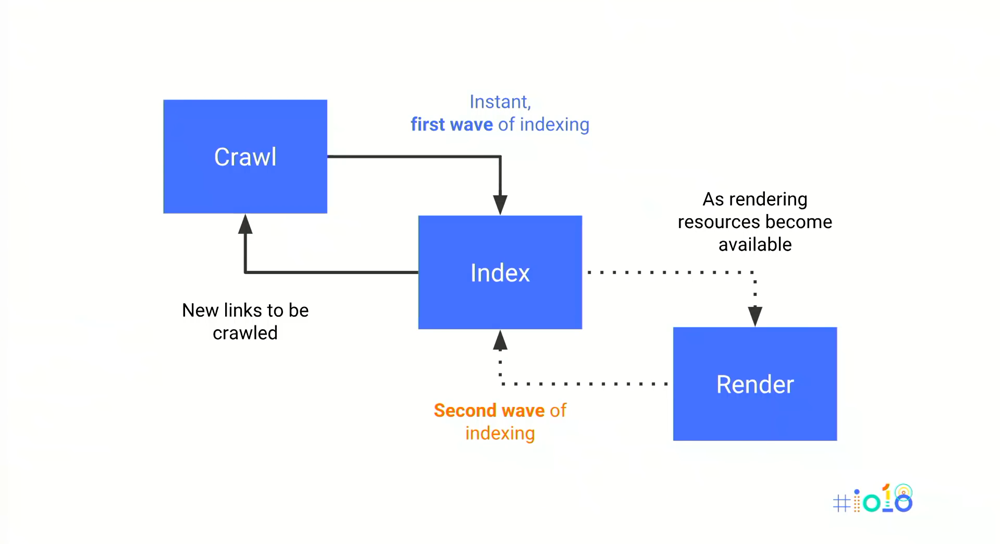
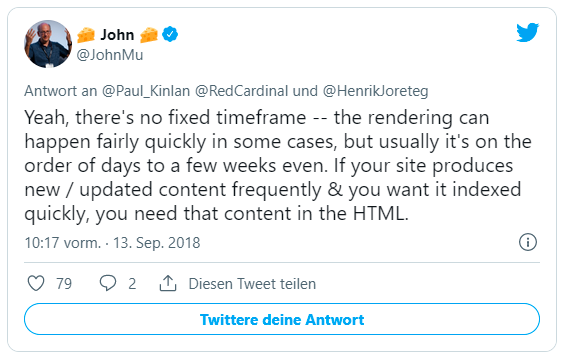
Google selbst spricht hier von „Second Wave of Indexing“. Hierbei wird erklärt, dass beim ersten Besuch (Crawl) das „Instant, first wave of indexing“ stattfindet. Es werden alle Inhalte direkt indexiert, ohne Rendering überhaupt anzuwenden. Was für Rich-JS-Webseiten fatal sein kann. Besonders wenn sich Inhalte oft ändern und aktuell sein müssen. Erst beim zweiten Besuch wird gerendert. Zwischen dem ersten und zweiten Besuch können aber auch mal ein paar Tage bis Wochen liegen, Zitat von Googles John Müller auf Twitter:
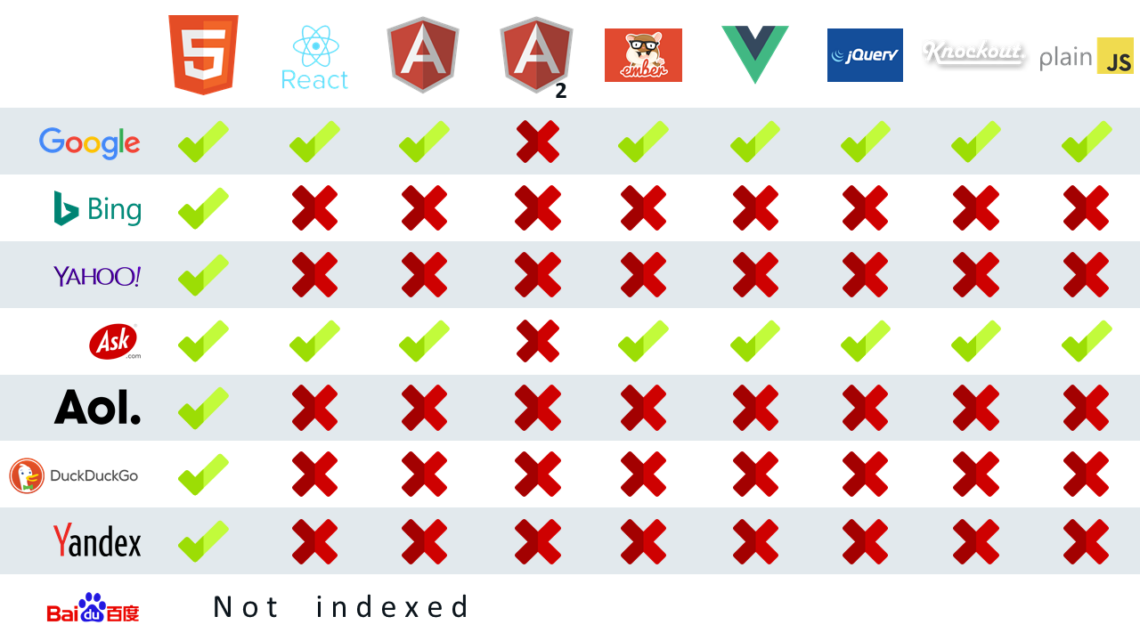
Google nutzt also eine Rendering-Engine für JavaScript- Wie sieht es aber mit anderen Suchmaschinen aus? Um diese Frage zu beantworten, hat der geschätzte Kollege Bartosz Góralwicz ein interessantes Experiment durchgeführt. Das Ziel des Experimentes war es, herauszufinden, wie Crawler mit welchen JavaScript-Frameworks umgehen können. Interessant zu sehen ist, dass bis auf Google (Ask bassiert auf Google) keine andere Suchmaschine in der Lage ist JavaScript zu rendern.
Abgesehen von diesem Experiment ist auch bekannt, dass Crawler von Facebook, Twitter, LinkedIn oder Xing aktuell auch kein JavaScript rendern. Nach dieser Erkenntnis werden lediglich die Technologien des Googlebots für die Interaktion mit JavaScript betrachtet.
Mit einer Server-Side gerednerten Rich-JS-Webstte schließt man alle anderen Suchmaschinen und soziale Netzwerke aktuelle aus!
Gerüchten zu folge scheint Bing lediglich bei großen Webseiten JavaScript zu rendern. Diese Aussage konnte lange Zeit nicht bestätigt werden. Der geschätzer Kollege Dan Patrovic hat auf Twitter gezeigt, dass die Webseite lendi.com die JavaScript Server-Side ausspielt von der Suchmaschine von Microsoft indexierte Inhalte aufweist.
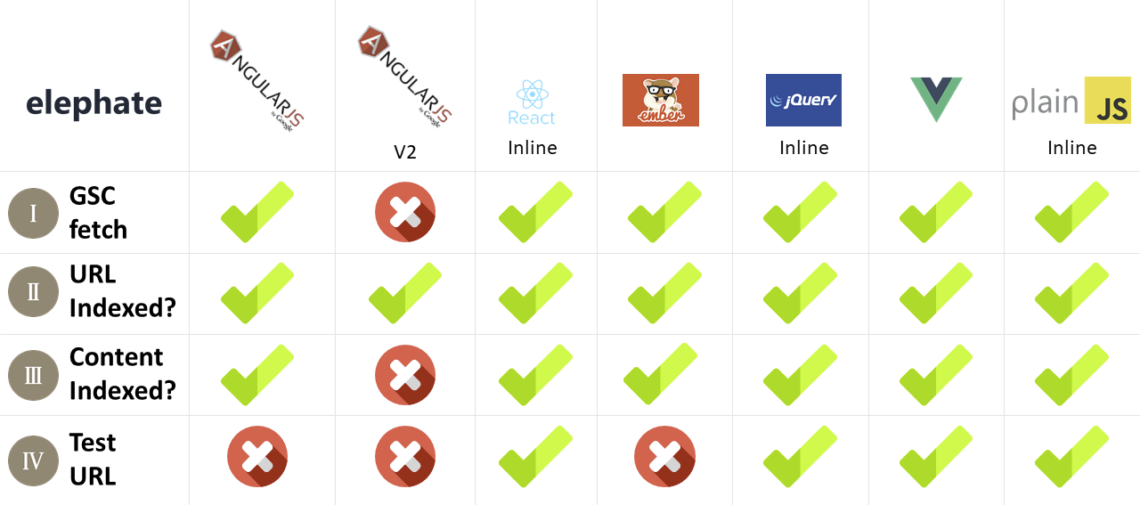
Um nochmals auf das Experiment von Bartosz Góralewisz zurückzukommen, wurde zwar festgestellt, dass Google aktuell die einzige Suchmaschine ist, die einen Crawler ins Rennen schickt, der auch JavaScript rendern kann, sich aber bei verschiedenen JavaScript-Frameworks auch unterschiedlich verhält.
Besonders bei extern aufgerufenen JavaScript hat der Crawler laut diesem Experiment Probleme Urls zu crawlen und diese zu besuchen. Deswegen kann davon ausgegangen werden, dass der Einsatz von Inline-JS die bessere Variante ist JavaScript zu implementieren, was gegen eine saubere Architektur spricht.
Fehler im Angular JS 2 Framework führte zu Crawling-Problemen
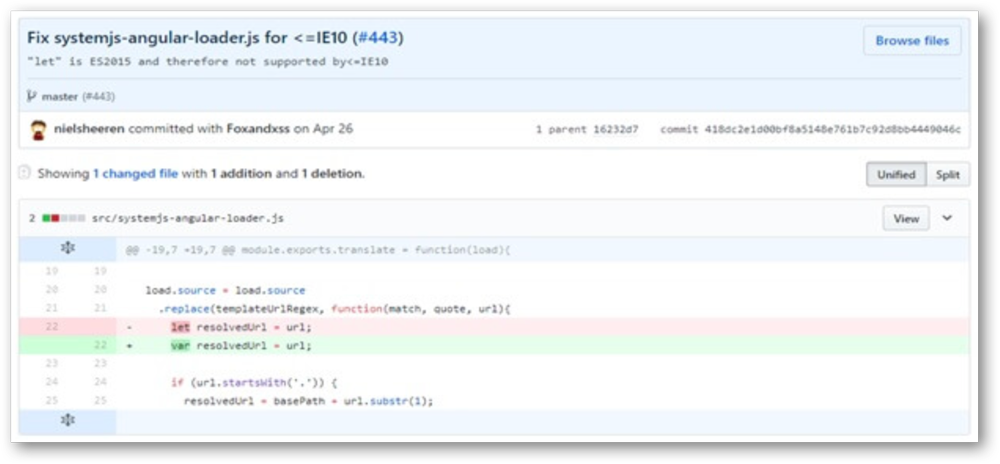
Besonders die Ergebnisse beim Angular JS 2 Framework hat viele Fragen aufgeworfen. Google hat Probleme ihr eigenes Framework zu crawlen? Nach langen Überlegungen konnte diese Frage aufgeklärt werden: Ein einfacher Fehler im Framework hat dazu geführt, dass Google selbst Probleme bei der Indexierung hatte. Nach eigenen Angaben von Google, wurde dieser Fehler am 26. April 2017 behoben, was die Indexierung des Angular JS 2 Frameworks ermöglichte. Dies ist ein weiteres Beispiel dafür, wie fehleranfällig JavaScript-Frameworks sind, wenn es um die Crawlbarkeit und Indexierbarkeit geht.
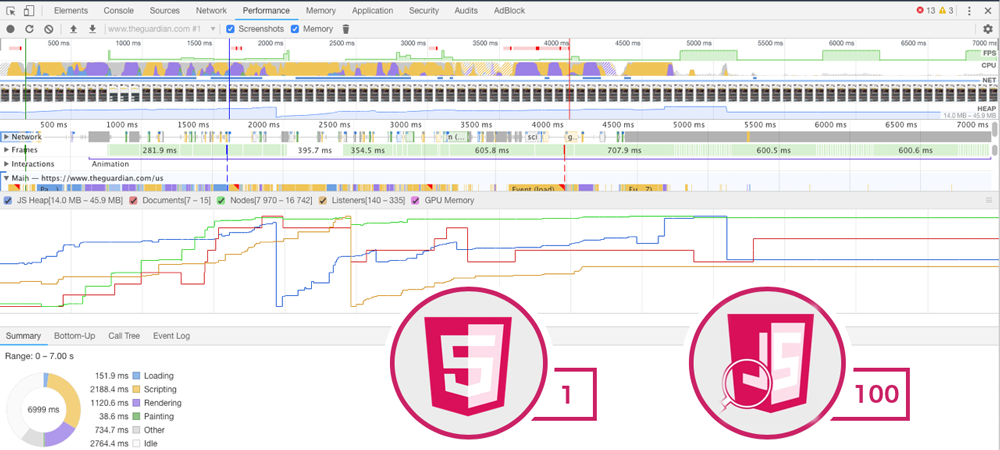
Ein wichtiger Punkt beim Rendern von JavaScript ist, dass dieser wie bereits vom Browser gerendert wird. der Browser greift für das Rendern auf die Hardware des Rechners, besonders auf die CPU. Was bedeutet, dass Rich-JS-Webseiten auf leistungsstarken Rechnern schneller lädt, als auf älteren schwächeren CPUs.
Diese Rechenleistung müssen Suchmaschinenkonzerne mitberücksichten, um JavaScript zu rendern. Diese Rechenleistung kostet natürlich mehr Geld als bei herkömmlichen HTML-Webseiten. Für Google ist es mit dem enormen Marktanteil keine große Schwierigkeit diese Rechenleistung, auch wenn nur limitiert, zu Verfügung zu stellen.
Konkurrenten wie Bing oder andere Suchmaschinen haben mit Ihrem nur sehr geringen Marktanteil nicht die nötigen Mittel um eigenes Rendering von JavaScript anzubieten. Man spricht davon, dass eine JavaScript-Website im Vergleich zu einer HTML-Webseite von gleicher größe etwa das hundertfache an Ressourcen benötigt um gerendert zu werden.
Aus diesem Grund ist es sehr unwahrscheinlich, dass andere Suchmaschinen mit eigenen Rendering-Engines nachziehen werden.
Um auf den nächsten Abschnitt dieses Beitrages zu Blicken, lohnt sich eine kurze Zusammenfassung der bis hier erläuterten Erkenntnisse:
- JavaScript wird vom Browser ausgeführt, nicht vom Server. Diese Aufgabe (rendern) muss der Crawler übernehmen, um Inhalte die durch JavaScript ausgeführt werden zu crawlen und zu indexieren.
- Ein Headless-Browser beschreibt relativ genau, wie ein Crawler mit einer Webseite interagiert.
- Der Googlebot verwendet zum Rendern von Webseiten den Web Rendering Service (WRS) welches immer auf der aktuellsten Google Chrome Browser Version basiert. Google arbeitet bereits an einem Upate
- Features und Technologien des Googlebots sind damit auf dem Stand vom Jahr 2015
- Die Developer-Tools des Google Chrome Browser kann neben dem „Url-Prüfen“-Tool der Google Search Console für Debugging und Testing von JavaScript verwendet werden.
- Das HTTP/2 Transfer Protokoll wird nicht unterstützt. Da es aber abwärtskompatibel ist, sollte es kein Problem darstellen.
- WebSocket-Protokoll, IndexedDB und WebSQL- Interfaces werden nicht unterstützt.
- Der Googlebot interagiert unterschiedlich mit verschiedenen JavaScript-Frameworks.
- Bis auf Google, rendert kein anderer Suchmaschinen-Crawler JavaScript.
- Googles Indexer (Caffein) ist für das Rendering geantwortlich, nicht der Crawler (Googlebot)
- Google rendert beim ersten Besuch einer Url JavaScript nicht, sondern Indexiert alles was ohne Rendering vorhanden ist.
- Lediglich Google rendert JavaScript. Andere Crawler von Suchmaschinen oder sozialen Netzwerken nicht.
- Das Rendern von JavaScript ist auch für Google Ressourcenintensiv
Da nun die Grundprinzipien von JavaScript und die dadurch entstehenden Schwierigkeiten bezüglich SEO bekannt sind, geht es in diesem Teil um hilfreiche Tools von Google aber auch externe Anbieter um JavaScript und SEO unter einen Hut zu bekommen.
Da das Rendering auf Basis des Chrome Browsers (WRS) basiert, eignet sich der hauseigene Browser von Google als Go-To Testingtool. Besonders die Konsole der JavaScript-Fehlern kann Auskünfte über Fehler und Warnungen geben. Besonders interessant ist die Betrachtung des gerenderten Codes.
Um JavaScript-Basierende Webseiten für SEO zu analysieren, muss nur ein kleiner Teil von JavaScript betrachtet werden. Im folgenden Abschnitt wird vereinfacht dargestellt, was passiert, wenn der Googlebot eine JavaScript-Basierende Webseite besucht.
Um diesen Ablauf zu simulieren, wird das integrierte Developer Tool im Google Chrome Browser genutzt.
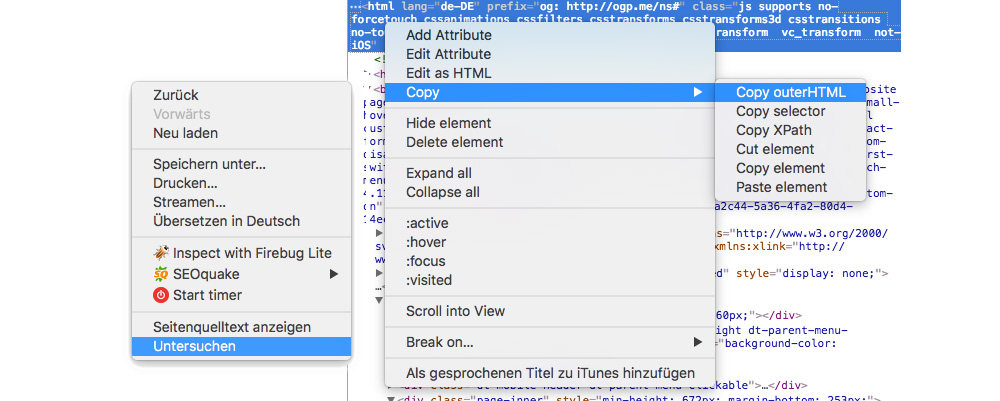
- 1.In einen „leeren Bereich“ der Webseite rechts-klicken und „Untersuchen“ auswählen
- 2.Um den gesamten Inhalt zu erhalten, den HTML-Tag im rechten Bereich des Browsers auswählen
- 3.Mit einem Rechtsklick auf den HTML-Tag auf „Copy“ und „Copy OuterHTML“ navigieren um den gesamten Inhalt zu kopieren
- 4.Der kopierte HTML-Code kann nun in Textprogramm eingefügt werden, um den Inhalt einzusehen und zu analysieren
Dieser Vorgang kann auch verwendet werden, um den Inhalt einer JavaScript-Basierenden Webseite auf OnPage-Faktoren zu überprüfen.
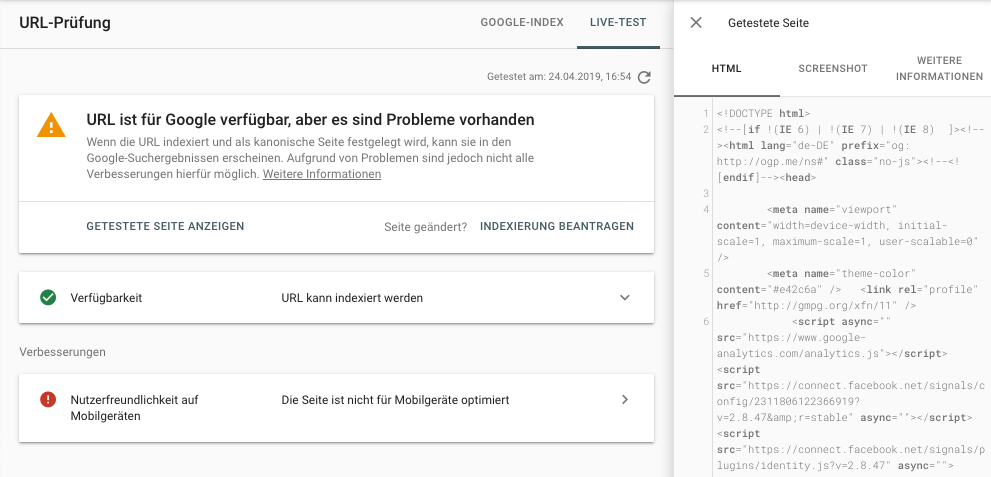
Naheliegend ist es natürlich, das „Url-Prüfungs-Tool“ der Google Search Console zu nutzen. Sehr hilfreich ist hier der Live-Test des Url-Prüfungs-Tools. Neben dem gerenderten HTML-Code und einem Screenshot von der gerenderten Webseite erhält man weitere Informationen, die vorallem für das Handling mit JavaScript sehr hilfreich sein können.
Hierbei sollte aber darauf geachtet werden, dass das Tool der Google Search Console lediglich Auskünfte darüber gibt, ob eine Webseite technisch gerendert werden kann oder bezüglich JavaScript Probleme beim crawlen auftreten. Timeouts und Performance-Ansprüche des GoogleBots werden hier nicht berücksichtigt.
Deswegen ist es immer zu Empfehlen eine Site-Abfrage inkl. Ausschnitt des zu überprüfenden Textes zu starten, um wirklich sicher zu gehen.
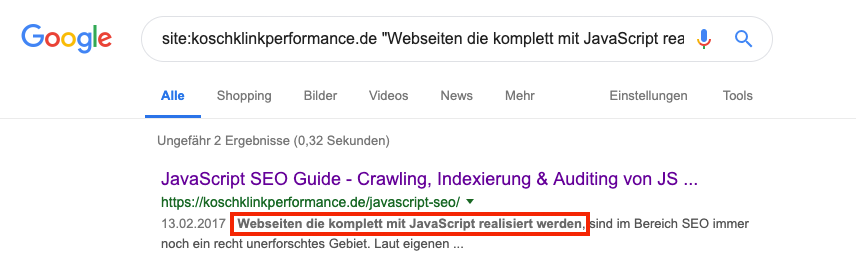
Um wirklich sicher gehen zu können, ob Inhalte gecrawlt und indexiert werden können, ist eine Site-Abfrage notwendig. Hierfür kann folgende Suchanfrage genutzt werden:
Site:deinedomain.de/deineseite „Zu testender Textauszug“
Auch wenn eine Url im Index ist, bedeutet es nicht, dass alle Inhalte einwandfrei indexiert wurden. Nur mit der Site-Abfrage in der Google Suche kann zu 100% sichergestellt werden, ob Google die Inhalte indexiert.
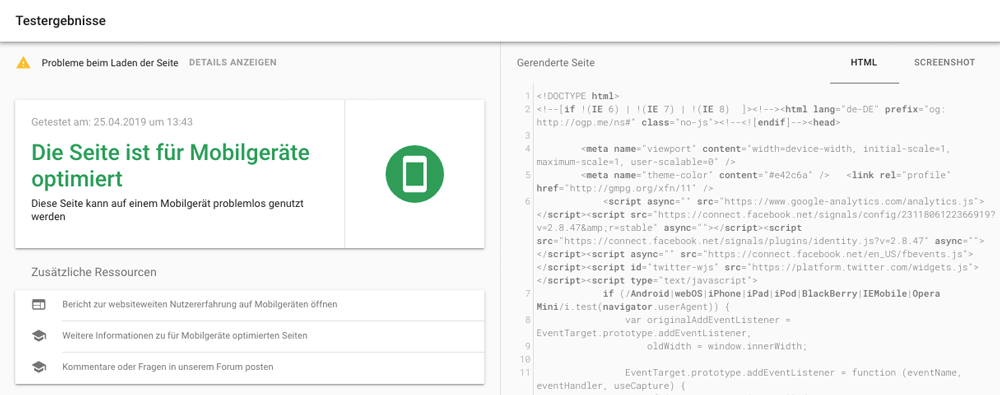
Vor der Einführung des „Url-Überprüfungs-Tool“ wurde der „Mobile Friendly Tester“ empfohlen, da laut eigenen Aussagen von Google (John Mueller) das bereits abgeschafte Fetch and Render Tool der Google Search Console einige Schwächen aufwies, wenn es um die Betrachtung des DOM geht. Deswegen wurde der Mobile Friendly Tester oder der Google Rich Media Tester empfohlen. Veränderungen die durch JavaScript am DOM nachträglich vorgenommen oder CSS-Anweisungen die z.B. durch Resizing verursacht werden, können mit dem Mobile Friendly Tester dargestellt werden.
Dank des „Url-Überprüfungs-Tool“ der Google Search Console ist der „Mobile Friendly Tester“ nicht unbedingt notwendig, kann aber auch zusätzlich genutzt werden. Interessant ist dieses Tool vorallem, um sich externe Seiten anzuschauen, deren Google Search Console Zugang nicht vorhanden ist.
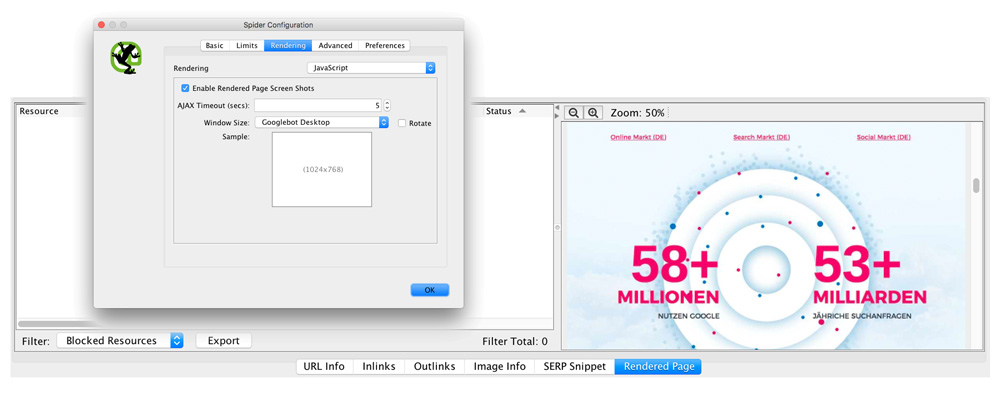
Eine Hilfestellung bietet der Screaming Frog SEO Spider. Dieser Crawler bietet bereits die Funktion, JavaScript zu rendern und erstellt ähnlich wie der Googlebot einen Screenshot der Webseite nach dem Load-Event.
Unter dem Menüpunkt „Configuration » Spider » Rendering“ kann hier der Punkt „JavaScript“ ausgewählt werden. Nach dem erfolgreichen crawlen der Webseite kann jede URL als „Rendered Page“ betrachtet werden. Dieser Screenshot kann bereits erste Aufschlüsse darüber geben, ob es Probleme beim Rendern der Webseite gibt. Zu beachten ist, dass diese Funktion lediglich in der Paid-Version des Screaming Frog SEO Spiders verfügbar ist.
Obwohl sich der Sreaming Frog SEO Spider ähnlich die der Googlebot verhält, ist leider damit nicht gewährleistet, ob der Googlebot exakt so verfährt und diese Seite genauso gerendert wird.
Des Weiteren ist vom Screaming Frog SEO Spider bekannt, dass dieser zwar die Rendering-Engine „Blink“ vom Chromium Project nutzt, diese sich aber von der des Googelbots (WRS) unterscheidet. Außerdem benötigt das Rendern (inkl. AJAX Timeout von 5 Sekunden) von JavaScript mit dem Screaming Frog SEO Spider große Ressourcen, was das Crawlen von JavaScript-Seiten mit mehr als 100.000 Urls quasi unmöglich macht.

Ryte bietet in der Business Suite für Ihre Kunden ebenfalls die Möglichkeit, Webseiten mit dem High-Performance Crawler mit JavaScript Crawling zu analysieren. Ryte nutzt beim Crawling den Google Chrome und versucht immer möglichst nah an der neusten Version zu bleiben. Dies ist natürlich bei Rich-JS-Webseiten sehr hilfreich um eine ausführliche OnPage-Analyse zu bekommen, da ohne JavaScript-Crawling der Crawler nicht sehen könnte.
Wir haben das große Glück den CO-Founder und Co-Geschäftsführer persönlich zu kennen, der wohl am besten erklären kann was der neue Ryte High-Performance Crawler mit JavaScript Crawling drauf hat:
Hallo Marcus, super, dass du Zeit gefunden hast, um uns ein paar Fragen zu eurem neuen JS-Crawler zu beantworten. Stell dich doch bitte kurz vor, wer du bist und was du bei Ryte machst.
Hallo, ich bin Marcus und ich liebe SEO 🙂
Ich bin Co-Gründer und Co-Geschäftsführer von Ryte und neben meinen Aufgaben als Geschäftsführer bin ich vor allem auch SEO Sparringspartner für unsere aktiven und potentiellen Business Suite Kunden.

Welche Rendering-Engine nutzt ihr um JavaScript auszuführen und wird es in Zukunft auch eine Funktion geben, um zwischen unterschiedlichen Engines zu wechseln?
Wir verwenden Google Chrome und versuchen immer möglichst nah an der neuesten Version zu bleiben. Der Wechsel der Engines ist nicht möglich und auch derzeit nicht geplant. Aber komplett ausgeschlossen ist es natürlich auch nicht.
Euer JS-Crawler hat etwas auf sich warten lassen. Welche Herausforderungen bzw. Ansprüche hatte ihr besonders an euren Crawler, wenn es um das Rendering von JavaScript geht?
Unsere Ansprüche haben wir für uns von Anfang an klar formuliert:
1) Stabil
2) Skalierbar
3) Wirtschaftlich
4) Unabhängig vom JavaScript Framework
5) Ergebnisse wie ein moderner Browser ausgeben
6) Kein “3rd party rendering”
7) Hohe Performance
Die Herausforderungen für uns sahen dabei folgendermaßen aus:
1) Welche Engine verwenden wir?
Die Engine sollte möglichst nah an einem Browser sein, sollte alle JavaScript Frameworks unterstützen, möglichst performant und durch Software steuerbar sein. Hier waren wir mit viel Recherche und Prototyping konfrontiert.
2) Wie können wir verteilt (distributed), skalierbar (scaleable) und belastbar (resilient) bauen und trotzdem wirtschaftlich bleiben?
3) Wie kann man die Ressourcennutzung (RAM, CPU) von Chrome reduzieren?
4) JavaScript an sich ist eine große Herausforderung, da es viele Probleme gibt, die man nur durch Testen herausfinden kann. Ein kurzes Beispiel: Wie behandelt man window.location Änderungen ohne Informationen zu verlieren? Viele dieser Fragestellungen sind initial gar nicht unbedingt auf der Agenda bis sie dann zum ersten Mal tatsächlich auftreten.
5) Die Ladezeiten von JavaScript Seiten sorgen für einen lang andauernden Crawl. Hier galt es, möglichst schnell unterwegs zu sein, um von Anfang an eine hohe Performance aufzuweisen.
Für wie wichtig haltet ihr es, dass euer Crawler so nah wie möglich an der Technologie von Google angelehnt ist, um Webseiten zu crawlen?
Google ist schlichtweg die bedeutendste Suchmaschine für unsere Zielmärkte. Damit macht es natürlich Sinn, sich technologisch an Google zu orientieren. Darüber hinaus hat Google auch für unser Tool eine hohe Bedeutung, da wir auf den Einsatz von 100% echten Google Daten setzen, um die Suchrealität abbilden zu können.
Kannst du jetzt schon etwas zu kommenden Features rund um das Thema JavaScript SEO für Ryte erzählen?
Wir planen keine expliziten JavaScript Features in den nächsten Monaten. Was wir aber berücksichtigen werden, sind Features, die auf Basis des Rendering umsetzbar sind. Wir haben da eine Menge spannender, neuartiger Ideen 🙂
Don’t just do it. Do it Ryte!
Danke, dass du dir die Zeit genommen hast, unsere Fragen zu beantworten. Wir freuen uns auf die weitere Entwicklung eurer Produkte.
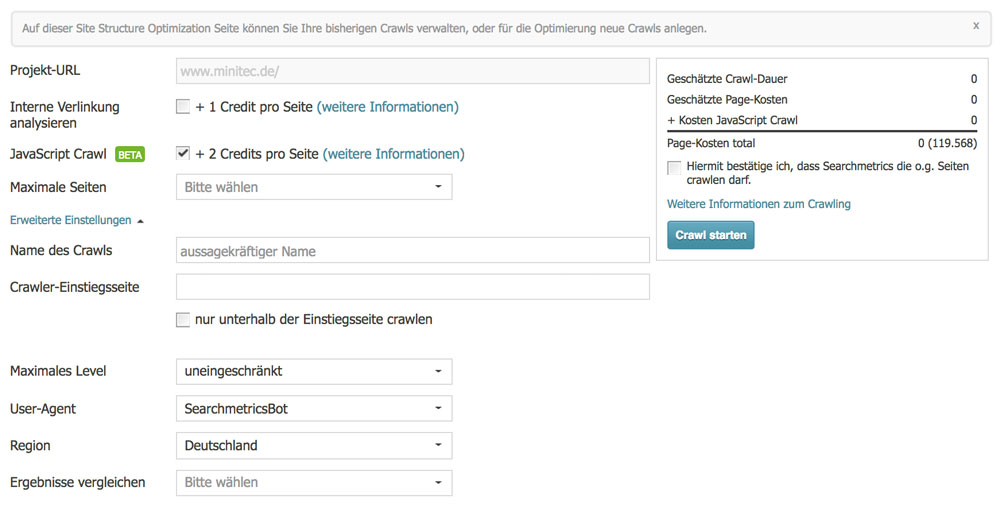
Die Searchmetrics Suite bietet mit der Site-Optimization ein JavaScript-Crawling an, welches auf dem Google Chrome und PhantomJS basiert. Damit bietet dieses Tool ein praktisches Werkzeug um SEO-Verantwortlichen die Arbeit zu erleichtern. Wir durften uns das Tool bereits anschauen und ausgiebig testen. Bei den Crawling-Einstellungen kann bereits gewählt werden, ob der Crawler JavaScript mitberücksichtigen soll. Da Searchmetrics bei diesem Crawl JavaScript ausführt, kann die Webseite hinsichtlich OnPage-Faktoren wie jede herkömmliche Webseite betrachtet werden, was einen große Hilfe für SEO-Verantwortliche bietet.
Freundlicherweise stand uns der Director für Product Marketing & Solutions, Malte Landwehr für ein kurzes Interview zur Verfügung, um unsere Fragen zu Searchmetrics JavaScript-Crawler zu beantworten:
Hallo Malte, super, dass du Zeit gefunden hast, um uns ein paar Fragen zu eurem neuen JS-Crawler zu beantworten. Stell dich doch bitte kurz vor, wer du bist und was du bei Searchmetrics machst.
Ich leite bei Searchmetrics die Bereiche Product Marketing und Product Solutions. Mein Team sorgt dafür, dass wir in der Produktentwicklung an den richtigen Themen arbeiten und dass unsere Kunden maximal von unseren Softwareinnovationen profitieren.

Und dann beschäftigen wir uns noch mit einer Million anderer Dinge wie Go-to-Market-Strategien, Release-Management, Pricing, Packaging, Sales Collateral, RFPs, usw.
Ich selbst wurschtel seit mehr als 10 Jahren im Online Marketing rum. Anfangs als Hobby, dann als Affiliate, Blogger und Freelancer. Dann war ich noch CoFounder einer SEO-Agentur in Münster und auf Kreta und hatte einen kurzen Ausflug in die Wissenschaft als ich mich für die Uni Münster, IBM, die DFG, die Vodafone Stiftung und die Konrad Adenauer Stiftung mit Social Network Analysis und dem politischen Diskurs auf Twitter beschäftigt habe. Zuletzt war ich Unternehmensberater und bin jetzt seit fast drei 3 Jahren bei Searchmetrics.
Wenn ich mich mal nicht mit SEO beschäftige, gehe ich meiner Kindle- und Netflix-Sucht nach.
Wieso ist es eurer Meinung nach beim Crawlen von Webseiten wichtig, auch JavaScript zu rendern?
JavaScript erlaubt es Websites mit viel besserer User-Experience zu erstellen als dies mit reinem HTML und CSS der Fall ist. Fast alle modernen Websites basieren heute auf Angular, React oder einem der vielen anderen JavaScript-Frameworks. Aus der modernen Webentwicklung ist JavaScript einfach nicht mehr wegzudenken.
Da auch Google JavaScript teilweise versteht, ist es wichtig bei der SEO-Bewertung von Websites auch DOM-Änderungen zu berücksichtigen, die nicht im puren HTML-Code stehen sondern durch JavaScript ausgelöst werden. Wenn eine Website via JavaScript den Title-Tag ändert und Inhalte nachlädt – und dies auf eine Art und Weise tut, die der Google Bot versteht – dann muss auch ein SEO-Crawler diese Änderungen verstehen um eine realistische SEO-Bewertung abzugeben.
Welche Rendering-Engine nutzt ihr um JavaScript auszuführen und wird es in Zukunft auch eine Funktion geben, um zwischen unterschiedlichen Engines zu wechseln?
Wir arbeiten mit Chrome und PhantomJS. Chrome ist natürlich näher am Google Bot, der aktuell auf dem Google Chrome basiert. PhantomJS hat den Vorteil, dass sich damit auch Websites crawlen lassen, mit denen Google Chrome nicht klar kommt.
Da wir als agile Software Company nicht mit starren Roadmaps arbeiten, spreche ich ungern über eventuelle zukünftige Funktionen. Ich kann so viel verraten: JavaScript-Crawling ist ein sehr wichtiges Thema für uns und wir machen uns intensiv Gedanken was für unsere Kunden am besten ist.
Für wie wichtig haltet ihr es, dass euer Crawler so nah wie möglich an der Technologie von Google angelehnt ist, um Webseiten zu crawlen?
Das halte ich für absolut essentiell um Kunden genau aufzeigen zu können, wie gut ihre Website für Google optimiert ist.
Allerdings geht unser Crawling-Anspruch etwas weiter als nur die Optimierung für Suchmaschinen. Kaputte Links können eine Auswirkung auf die User Experience haben. Für eine JavaScript-lastige Shopping-Website kann es also durchaus ein Mehrwert sein, wenn wir die Seite wie ein Mensch crawlen und nicht wie Google.
Nach offiziellen Aussagen der Suchmaschinen-Konzerne, ist aktuelle nur Google in der Lage, JavaScript zu rendern. Sobald andere Suchmaschinen nachziehen, werden diese sicherlich ihre eigenen Technologien einsetzen. Wie weit wird das in eurem Crawler mitberücksichtigt werden, wenn es soweit ist?
Wir unterstützen aktuell in der Searchmetrics Suite ein knappes Dutzend Suchmaschinen. Neben Google, Yahoo, Baidu und Yandex auch so Exoten wie Qihoo 360 und Sogou. In Amerika und Europa ist aber für eigentlich jeden Kunden Google das Maß der Dinge. Die meisten SEOs die ich kenne, prüfen nie wie Bing und Yahoo mit Noindex, Nofollow oder der robots.txt umgehen. An diesem Google-Fokus wird meiner Meinung nach auch JavaScript-Crawling nichts ändern.
Da Microsoft hochwertige Progressive Web Apps über den Bing Crawler aufspüren und über den Microsoft Store direkt in Windows verfügbar machen möchte, werden wir sicher in Zukunft deutlich mehr JavaScript Crawling aus dem Hause Microsoft sehen. Und damit wird das Thema JavaScript-Crawling/PWA-Crawling dann auch deutlich über den SEO-Tellerrand hinaus spannend! Denn es ist vermutlich nicht der Head of SEO, der sich damit befasst ob die eigene PWA gut in Windows 10 funktioniert und wie sie im Windows Store gelistet wird.
Danke, dass du dir die Zeit genommen hast, unsere Fragen zu beantworten und vielen Dank, dass wir euren Crawler ausgiebig testen durften. Wir freuen uns auf die weitere Entwicklung eurer Produkte.
Um auf den nächsten Abschnitt dieses Beitrages zu Blicken, lohnt sich eine kurze Zusammenfassung der bis hier erläuterten Erkenntnisse:
- Mit dem Google Chrome Browser in der aktuellen Version werden Webseiten mit den selben Features gerendert. Damit ein sehr wichtiges Testing-Tool
- Die Chrome Developer Tools ermöglichen den gerenderten Code darzustellen und Fehler beim Rendering zu identifizieren
- Der Live-Test im „Url-Überprüfen“-Tool hilft beim Auditing von Fehlern und zur Betrachtung des von Google gerenderten Code
- Lediglich eine Site-Abfrage in dern Google-Suche gibt valide Aussagen ob Inhalte indexiert wurden
- Neben der Google Search Console dient Googles Mobile Friendly Tester als Audting-Tool. Besonders bei externen Webseiten ohne Zugriff auf die GSC
- Der Screaming Frog SEO Spider mit einer eigenen Rendering Engine eigenet sich gut für kleinere Webseiten
- Mit dem Ryte High-Performance Crawler mit JavaScript Cralwing können auch OnPage-Analysen erstellt werden, trotz Client-Side-Rendering JavaScript
- Searchmetrics bietet in ihrer Suite ebenfalls die Möglichkeit Webseiten mit Client-Side-Rendering JavaScript zu crawlen
Im Folgenden werden die wichtigsten Empfehlungen und Best Practice Beispiele erklärt, um JavaScript und SEO am besten zu verheiraten. Viele der Tipps stammen direkt von Google und sollen helfen grobe Fehler zu vermeiden
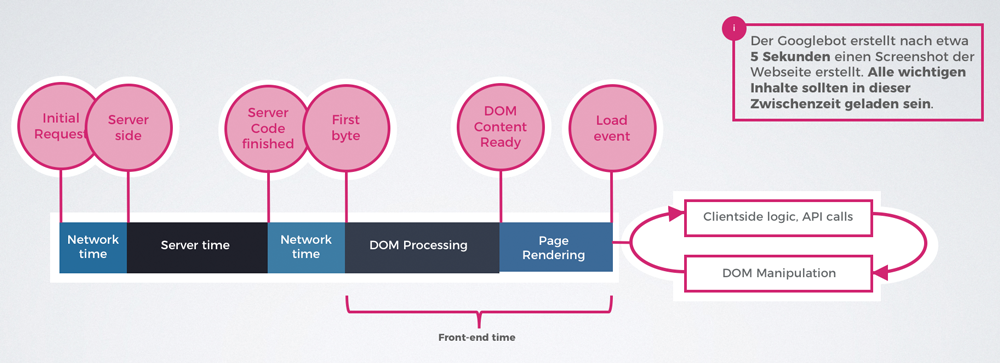
Da Google den gerenderten Quellcode direkt nach dem Load-Event crawlt, werden alle dynamischen Inhalte die während bzw. nach einem User-Event geladen werden, gänzlich ignoriert. Der Load-Event ist beendet, wenn die Seite komplett geladen wurde. Hierbei sollte beachtet werden, dass der Googlebot nach etwa 5 Sekunden einen Screenshot der Webseite erstellt. Alle wichtigen Inhalte sollten in dieser Zwischenzeit geladen sein.
User-Events führen dazu, dass JavaScript den Quellcode einer Webseite verändert. Dies kann ebenfalls mit dem integrierten Developer Tool im Google Chrome Browser simuliert und veranschaulicht werden. Ein User-Event kann z.B. ein Klick (onClick) auf einen Tab sein, der weitere Inhalte zum Vorschein bringt. Aus diesem Grund ist es wichtig, dass alle wichtigen Inhalte die von Google gecrawlt werden sollen, auf der Seite dargestellt werden, ohne das eine Interaktion des Webseitenbesuchers notwendig ist.
Es konnte weiter beobachtet werden, dass Google auch Inhalte indexiert, die erst durch ein User-Event erstellt werden. Der Grund dafür kann sein, dass ein Headless-Browser auch durch Befehle mit der Webseite interagieren kann. Hier war kein klares Muster zu erkennen, da andere Inhalte gänzlich ignoriert wurden. Deswegen die Empfehlung, alle wichtigen Inhalte bereitzustellen ohne die Notwendigkeit eines User-Events.
Wie oben bereits erwähnt, dient das Url-Überprüfen-Tool der Search Console und der Google Chrome als valide Quellen für das Testing und Debugging von JavaScript für SEO. Trotz dessen, konnten beim Testing unterschiedliche Ergebnisse zwischen dem Url-Überprüfen-Tool dem tatsächlichen Renderingverhalten des Googlebots.
Dies lag vorallem daran, dass der Googlebot nach 5 Sekunden einen Screenshot der Webseite erstellt. Damit werden alle Inhalte, die erst nach den 5 Sekunden gerendert wurden, nicht unbedingt indexiert. Darauf sollte beim Testing unbedingt geachtet werden.
Dieses Tatsache bestätigt ein spannendes Experiment von Tomasz Rudzi im Elephate-Blog der mit dem damaligen „Fetch and Render Tool“ der Google Search Console welches bereits vom „Url-Überprüfungs-Tool“ abgelöst wurde, zeigte.
In diesem Experiment wurden Textinhalte über JavaScript erzeugt, die aber erst nach 2 Minuten auf der Webseite sichtbar waren. Bei der Betrachtung im Fetch and Render Tool der Google Search Console wurden diese Inhalte, die mit einer Verzögerung von 2 Minuten vom JavaScript erzeugt wurden, einwandfrei dargestellt. Bei der Betrachtung einer Site-Abfrage konnte aber festgestellt werden, dass er Indexer nicht so geduldig war. Die verzögerten Inhalte wurden von Google nicht indexiert.
Für die URL-Struktur sollten bei JavaScript-Basierenden Webseiten ein paar Punkte beachtet werden. Es ist wichtig sicherzustellen, dass beim Aufruf von Seiten jeweils neue URLs aufgerufen werden. Das bedeutet, dass jeder Seite einer Domain eine eigene URL zugeordnet wird.
Des Weiteren sollten alle eigenständigen URLs ohne Hash „#“ realisiert werden, da Google die Angaben in der URL nach dem „#“ ignoriert. Dies führt dazu, dass Google alle internen Verlinkungen als Links zur Startseite identifizieren würde und keinen weiteren Links folgen würde. Für Sprungmarken kann ein Hash „#“, wie auch bei herkömmlichen Webseiten, verwendet werden. Zu empfehlen sind auch bei JavaScript-Basierenden Webseiten „sprechende“ URLs.
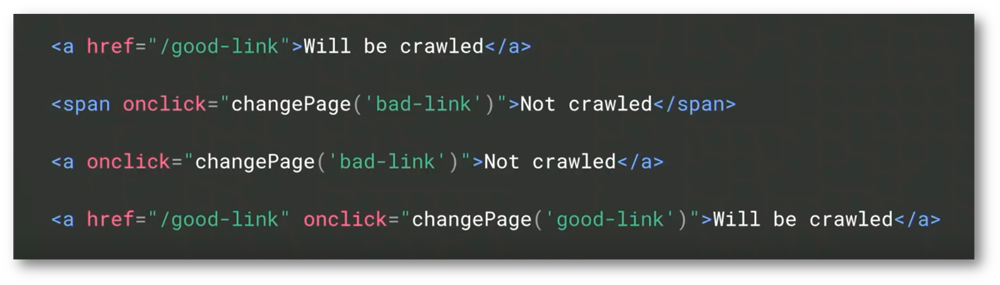
Um dem Googlebot das crawlen von Links zu ermöglichen, sollten alle Links über den HTML A‑Tag realisiert werden. Auch hier sollte darauf geachtet werden, dass diese Links nicht durch ein User-Event (z.B. onClick) aufgerufen werden.
Des Weiteren sollte darauf geachtet werden, dass pushState-Fehler vermieden werden, damit die original URL mit serverseitiger Unterstützung weitergegeben wird.
Im Hinblick auf das „Second Wave of Indexing“ sollten vorallem Canonical-Tags im Head-Bereich bereits crawlbar sein, ohne das JavaScript gerendert werden muss. Google selbst gibt diese Empfehlung:

Spannend zu diesem Thema ist das Experiment von Eoghan Henn, der versucht hat Canonical-Tags per JavaScript auszuspielen. Das Ergebniss war, dass Google wohl doch die knaonisiserten Urls indexiert hat, aber erst nach 34 Tagen. Dieses Experiment zeigt nochmal, wie lange es dauern kann, bis Google Inhalte die durch JavaScript erzeugt werden verarbeitet und indexiert. Daher klare Empfehlung: Canonical-Tags ohne notweniges Rendern von JavaScript ausgeben.
Wie bereits im oberen Abschnitt erwähnt wurde, sind Crawler von anderen Suchmaschinen und sozialen Netzwerken noch nicht in der Lage, JavaScript zu rendern. Um diesen Crawlern wichtige Informationen wie Title-Tag, Meta-Description, Cannonical-Tag, Meta-Robots-Angaben und wenn vorhanden OpenGraph-Angaben bereit zu stellen, sollten diese Inhalte ohne vorher gerendert werden zu müssen, im Head-Bereich der Webseite aufrufbar sein.
Google selbst empfiehlt für strukturierte Daten bei JavaScript-Basierenden Webseiten den Einsatz von JSON-LD. Allgemein empfiehlt sich der Einsatz von JSON-LD für alle Arten von Webseiten.
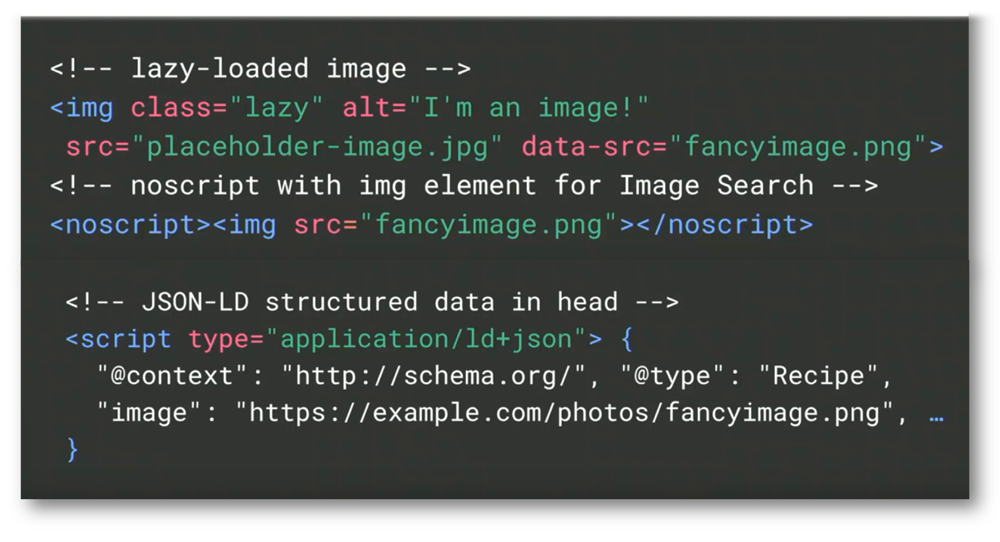
Beim Einsatz von Lazy-Loading für Bilder gibt Google klare Empfehlungen diese entweder über ein Noscript oder über schema.org mittels JSON-LD zu lösen. Ähnlich wie bei der Vorgabe von Verlinken ist es, dass die Url des Bilder direkt ohne nötiges Rendering im Quellcode vorhanden ist.

Google das Crawlen nach altem AJAX-Schema bereits 2018 einstellt. Johannes Müller hatte in einem Webmaster-Hangout mitgeteilt, dass keine Escaped-Fragment-URLs wie „/page?query&_escaped_fragment=key=value“ mehr aufgerufen würden.
Die Suchmaschine Bing hinsichtlich unterstützt weiterhin das AJAX-Schema.
Zur Übersicht wurden hier nochmals alle Best-Practice-Beispiele zusammengefasst:
- Analyse vom Quellcode (Pre-DOM) reicht nicht aus, da erst der gerenderte Code alle Inhalte anzeigt
- Inhalte müssen nach dem Load-Event dargestellt werden. Inhalte die durch ein User-Event erzeugt werden, können nicht indexiert werden
- Suchmaschinenrelevante Inhalte sollten innerhalb von 5 Sekunden gerendert und geladen sein
- Beim Aufruf einer Seite muss eine eigene Url mit serverseitiger Unterstützung erzeugt werden
- Kein Einsatz von Hash (#) in der Url, da alles was nach einem Hash folgt, vom Crawler gänzlich ignoriert wird
- pushState-Fehler sollten vermieden werden, damit die original URL mit serverseitiger Unterstützung weitergegeben wird
- Links über a‑href realisieren und nicht durch User-Events (z.B. onClik) erzeugen lassen
- Canonical-Tags sollten ohne notweniges Rendern von JavaScript im Header geladen werden
- Beim Einsatz von Lazy Loading für Bilder muss der Dateiname im Quellcode vorhanden sein
- Strukturierte Daten sollten mit JSCON-LD realisiert werden
- Google hat das Crawling vom AJAX-Schema 2018 eingestellt.
Nachdem bereits alle wichtigen Problematiken Hinsichtlich JavaScript und SEO aufgeklärt wurden, dass kein SEO-Verantwortlicher mit einer Rich-JS-Webseite 100% sicher gehen kann, dass seitens der Suchmaschine alles einwandfrei abläuft. Hier kommt das Thema „Prerendering“ ins Spiel. Was das genau ist, wieso es für SEO-Verantwortliche wahrscheinlich die beste Lösung ist und alles weitere wichtige zu dem Thema, gibt es im folgenen Abschnitt.
Wie bereits angesprochen, ist lediglich der Crawler von Google in der Lage JavaScript zu rendern. Wenn man einen Wert auf andere Suchmaschinen und besonders soziale Netzwerke wie Facebook, Twitter, Instagram, Xing etc. legt, sollte eine Möglichkeit gesucht werden, auch diesen Crawlern das Auslesen der Inhalte zu ermöglichen. Prerendering, also Server-Side Rendering ist hier eine mögliche Lösung.

Prerendering führet dazu, dass JavaScript vorgerendert wird. Das bedeutet, dass der Googlebot und alle anderen Crawler bereits den gerenderten HTML-Code bereitgestellt bekommen und nicht selbst rendern müssen um die Inhalte crawlen zu können. Das bringt den großen Vorteil mit sich, dass ganz genau sichergestellt werden kann wie der HTML-Code der dem Googlebot bereitgestellt wird aussieht.
Wer sich nicht selbst um ein serverseitiges Rendering von JavaScript kümmern möchte, kann auf kostenpflichtige Dienste wie Prerender.io setzten. Nach der erfolgreichen Implementierung des Dienstes wird die gesamte Webseite gerendert und auf dem Server gespeichert (Cache). Wie oft der Cache aktualisiert wird, hängt von dem jeweiligen Dienstleister ab.
Bei einer Anfrage an den Server wird nun geschaut, welcher User-Agent hinter einer Anfrage steckt. Wenn es sich hier um ein Bot wie z.B. den Googlebot handelt, wird diesem der bereits zwischengespeicherte, also gerenderte Code zur Verfügung gestellt. Damit erspart sich der Crawler das Rendern von JavaScript bzw. ermöglicht es Crawlern, die nicht in der Lage sind JavaScript auszuführen die Inhalte der Webseite zu erfassen.
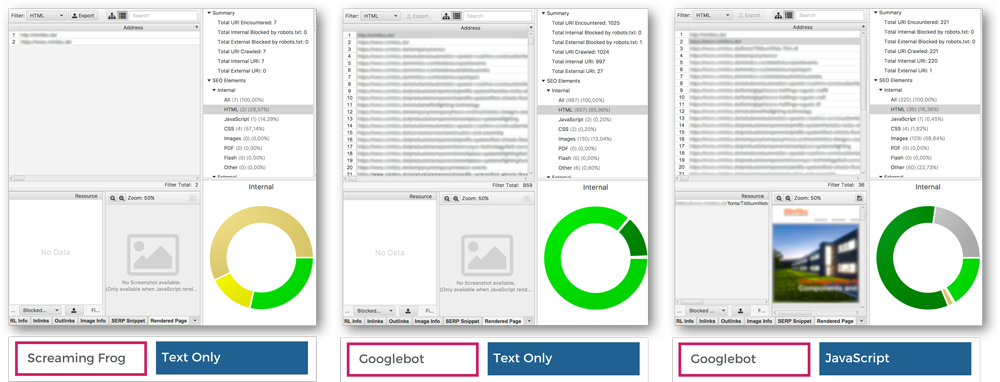
Um den korrekten Einsatz von Prerendering-Diensten extern zu testen, empfiehlt sich der Einsatz des Screaming Frog SEO Spiders. In Abbildung 27 sind drei Test-Szenarien zu sehen.
- Test-Scenario: User-Agent: Screaming Frog, Rendering: Text Only. Hier ist zu erkennen, dass der Crawler bis auf die Startseite keine weiteren Urls gecrawlt hat, da das JavaScript nicht ausgeführt wurde.
- Test-Scenario: User-Agent: Googlebot, Rendering: Text Only. Hier ist zu erkennen, dass alle Urls gecrawlt wurden da der Prerendering-Dienst den User-Agent Googlebot erkannt hat und den vorgerenderten Code ausgegeben hat
- Test-Scenario: User-Agent: Googlebot, Rendering: JavaScript. Auch hier ist zu erkennen, dass alle Urls gecrawlt wurden da die Rendering-Engine vom Screaming Frog aktiviert wurde
Zu Vermerken ist, dass sobald beim Screaming Frog die Rendering-Engine aktiviert wird, der Crawler auch JavaScript ausführt, egal welcher User-Agent hinter der Anfrage steckt.
Testing von Prerendering mit dem User-Agent-Switcher
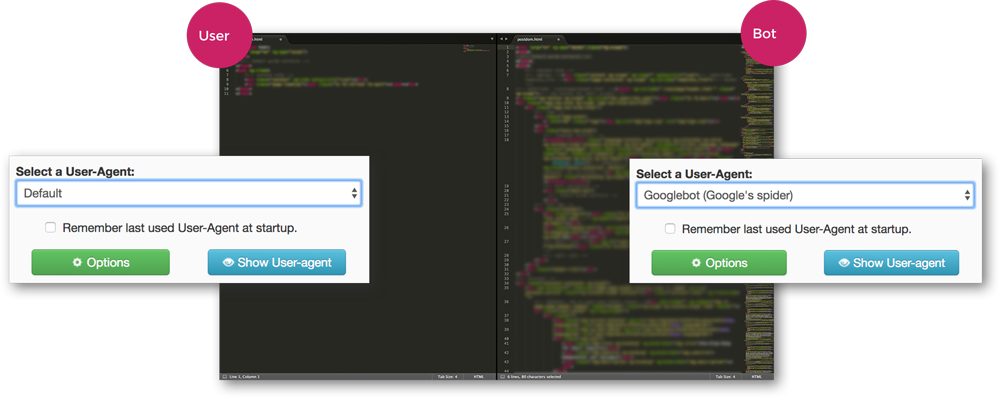
Neben dem Screaming Frog SEO Spider eignet sich auch der Google Chrome Browser für das Testing von Prerendering-Diensten. Hierfür muss das kostenlose Add-On „UserAgent-Switcher“ installiert werden.
Mit dem UserAgent-Switcher kann der User-Agent beliebig manipuliert werden. Im ersten Fall, welcher in Abbildung 28 zu sehen ist, wurde der User-Agent auf „Default“ gestellt. Bei der Betrachtung des Quellcodes ist zu sehen, dass hier kein JavaScript ausgefuhrt wurde.
Im zweiten Fall wurde der User-Agent „Googlebot“ gewählt und die Webseite erneut besucht. Bei der Betrachtung des Quellcodes ist zu sehen, dass hier der vorgerenderte Code an den Brower ausgeliefert wurde, da der Prerendering-Dienst den Googlebot als UserAgent erkannt kann.
Bei solchen Tests sollte darauf geachtet werden, dass der Cache des Browsers bei jeder neuen Anfrage an den Server gelöscht werden sollte.
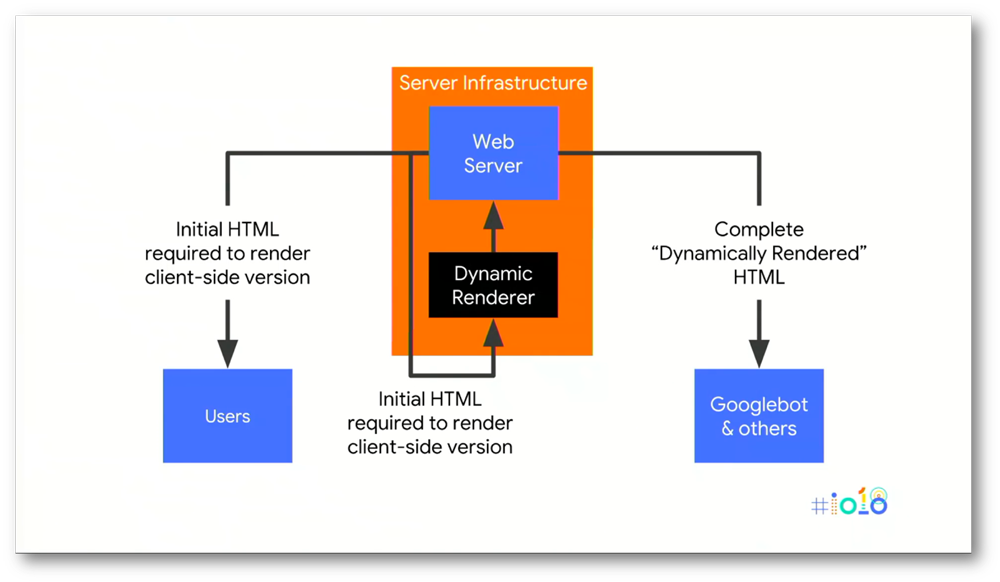
Spannden ist, dass Google selbst, zumindest laut eigener Aussage in den meisten Fällen zu Prerendering rät. Google nutzt hierfür den eigen erfundenen Namen „Dynamic Rendering“, was nichts anderes ist als das hier angesprochene Prerendering, also eine Lösung in dem JavaScript bereits vom Server gerendert wird. Google gibt hinsichtlich noch den Tipp, dass für das Rendern ein seperater Server genutzt werden soll, da das Rendern die Server zu sehr belasten könne. Dynamic Rendering wurde zum ersten mal auf der Google I/O 2018 präsentiert:
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Google nutzt für YouTube ebenfalls Prerendering
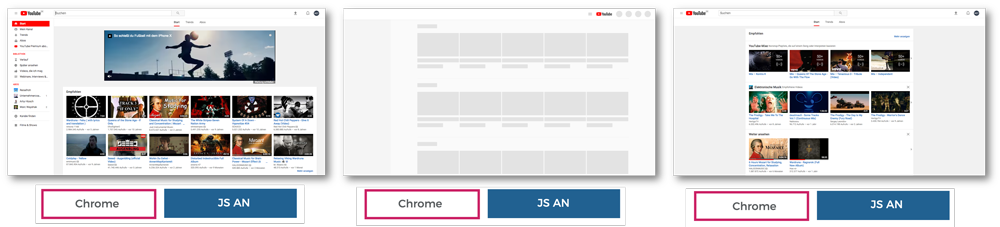
Interessant zu beobachten ist, dass Google für ihre Hauseigene Vidoplatform YouTube selbst Prerendering Einsetzt. Dies lässt sich in dem oben erklärten Ablauf einfach testen. Mit dem Standard User-Agent von Chrome und aktivirtem JavaSript lädt die Webseite wie gewohnt. Sobald JavaScript im Browser deaktiviert wird, sind keine Inhalte mehr zu sehen, da bei YouTube alle Videos über JavaScript erzeugt werden. Sobald der User-Agent zusätzlich auf Googlebot gestellt wird, ist die vorgerenderte Version der Webseite zu sehen. Die wichtigsten Inhalte, auch wenn in einer etwas anderen Darstellung, werden angezeigt.
Ob es sich hierbei wirklich um Prerendering handelt ist nicht sicher. Es ist aber deutlich, dass Google dem Crawler eine gesonderte Version zur Verfügung stellt, ohne JavaScript rendern zu müssen. Bei dem täglichen Neuaufkommen von Videos eine verständliche Maßnahmen Seitens Google.
Ob beim Einsatz von Prerendering auf eigene Lösungen oder kostenpflichtige Dienste gesetzt wird, gibt es keine eindeutige Antwort und sollte selbst abgeschätzt werden. Besonders der Faktor kosten und Aufwand spielt hier eine große Rolle.
Google selbst empfiehlt den Einsatz vom Kostenpflichtigen Dienst wie Prerender.io und als eigene Lösungen Renderton oder Puppeteer. Desweiteren wäre noch Phantom.js zu empfehlen.
In einem Beispiel zeigt Jesse Hanley was passieren kann, wenn der externe Dienst streiken sollte oder es Probleme bei der Abrechnnung gab:
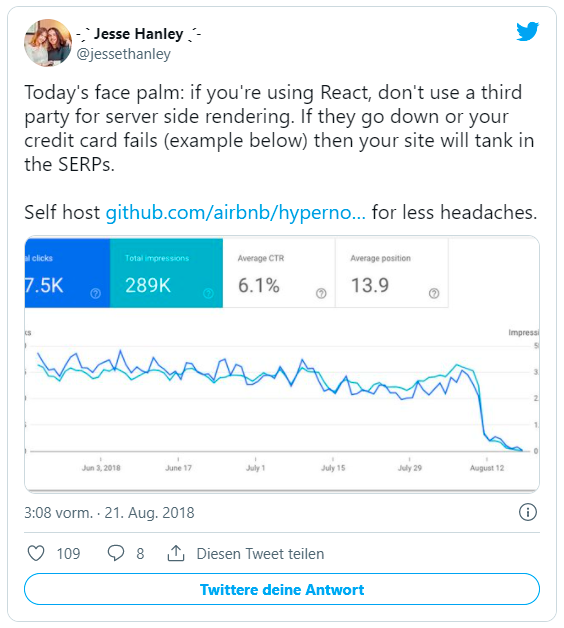
Bei all diesen Vorteilen, bringt serverseitiges Rendern von JavaScript auch einige Nachteile für SEO mit sich. Da dem User und dem Crawler unterschiedliche Wege bis zum Aufruf der Inhalte präsentiert werden, entsteht eine Gefahr von Cloaking. Auch wenn sich die Gefahr in Grenzen hält, sollte jeder SEO-Verantwortliche bei der Entscheidung diesen Punkt mitberücksichtigen.
Des Weiteren ist durch das längere zwischenspeichern der Webseite, „Realtime Content“ nur in begrenzten Möglichkeiten einsetzbar. Änderungen werden dementsprechend erst beim nächsten „Caching“ der Webseite für den Crawler sichtbar. Damit erhöht sich die Gefahr von Cloaking.
Durch eine saubere Implementierung von Prerendering auf dem Server entstehen größere Aufwände. Auch wenn auf externe Prerendering-Dienste zurückgegriffen wird, fallen monatliche Kosten auf. Diese Staffeln sich meist je nach Webseitengröße und der Frequenz der zwischengespeicherten Version der Webseite auf dem Server.
Zu weiteren Nachteilen gehört, dass die selbe Version einer Webseite für verschiedene Endgeräte bereitgestellt wird. Bei der Nutzung von Responsive-Design und Responsive –Content muss der DOM erneut geladen werden, um jeder Bildschirmauflösung gerecht zu werden.
All diese Nachteile sollten bei der Nutzung von Prerendering in Betracht gezogen und validiert werden.
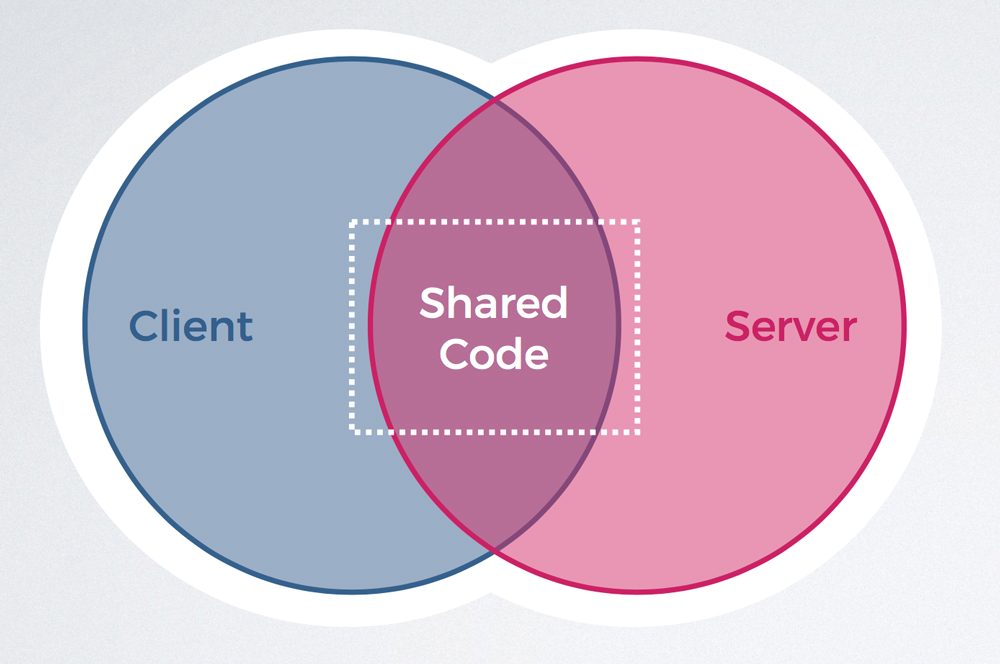
Isomorphic JavaScript bzw. Universal JavaScript bietet hier Abhilfe und verspricht die Wunderwaffe im Zusammenspiel von JavaScript und SEO zu sein. Was ist Isomorphic JavaScript und wieso ist es im Bereich SEO so interessant?
Was ist Isomorphic JavaScript?
Mit dem Einsatz von Isomorphic-Lösungen wird der JavaScript-Code sowohl vom Server als auch vom Client ausgeführt. Das bedeutet, dass dem Client ein bereits gerenderter Code präsentiert wird. Das spannende dabei ist, dass JavaScript Inhalte im Browser trotzdem verändern kann. Dadurch können weiterhin dynamische Inhalte abgebildet werden und der Crawler bekommt den gerenderten Code präsentiert. Dieser „Shared-Code“ wird damit sowohl vom Browser, als auch vom Crawler genutzt.
Mit dieser Lösung wird dem Crawler das Rendern von JavaScript erspart und der Client profitiert von der besseren Performance, da der vorgerenderte Code direkt dargestellt werden kann. Damit wären die größten Schwierigkeiten beim Zusammenspiel von JavaScript und SEO gelöst.
Nachteile von Isomorphic JavaScript?
Nur bestimmte JavaScript-Frameworks eigenen sich ohne Weiteres für den Einsatz von Isomorphic-Lösungen. Andere Frameworks lassen sich nur über Umwege und deutlich höheren Aufwand für solch ein Projekt anpassen.
Da dieses Themengebiet noch sehr neu und unerprobt ist, benötigt es ein hohes Maß an Erfahrung und Knowhow auf Seiten des Entwickler-Teams. Besonders Testing und Debugging von Isomorphic JavaScript benötigt eine weitaus größere Aufmerksamkeit als herkömmliche JavaScript-Lösung im Bereich SEO. Damit ist dieser Ansatz für kleinere Projekte mit geringem Budget gänzlich unattraktiv.
Nicht desto Trotz, bietet Isomorphic JavaScript in Zukunft eine vielversprechende Lösung um SEO und JavaScript zu verheiraten.
Zur Übersicht wurden hier nochmals alle wichtigen Punkte die für Prerendering (Server-Side-Rendering) für JavaScript-Webseiten wichtig sind zusammengefasst:
- Ohne Prerendering werden alle anderen Suchmaschinen und soziale Netzwerke ignoriert
- Beim Einsatz von Prerendering wird dem Crawler eine bereits vorgerenderte (cache) Version der Seite präsentiert. Der User profitiert somit weiterhin von allen Client-Side-Rendering Vorteilen von JavaScript
- Mit dem Screaming Frog SEO Spider und der Google Chrome Erweiterung User Agent Switcher lässt sich Prerendering extern einfach testen
- Google selbst empfiehlt in den meisten Fällen Prerendering (Dynamic Rendering)
- Sowohl eigene Lösungen als auch kostenpflichte Dienste für Prerendering kommen in Frage
- Isomorhic (Universal) JavaScript bietet in ferner Zukunft die optimale Lösung, steckt aktuell aber noch in den Kinderschuhen
Abschließend einige Gedanken zu JavaScript SEO, welche Punkte es SEO-Verantwortlichen erschwert JavaScript und SEO unter einen Hut zu bringen, welche neuen Ansätze geschaffen werden müssen und wo der Weg hingehen sollte.
Alleine die Schwierigkeit, dass nur Google als bislang einzige Suchmaschine JavaScript rendern kann, erschwert es SEO-Verantwortlichen den Umgang mit JavaScript. Auch wenn andere Suchmaschinen nachziehen, werden diese sehr wahrscheinlich andere Technologien und Renderning-Engines nutzen, um JavaScript ausführen zu können. Zusätzlich muss mit unterschiedlichen JavaScript-Frameworks anders umgegangen werden.
Wie sieht es mit dem Auditing und Testing aus? Da kaum Tool-Anbieter überhaupt das Rendering von JavaScript anbieten, wenn überhaupt, dann mit unterschiedlichen Rendering-Engines, sind diese Tools kaum bis gar keine validen Quellen auf die sich SEO-Verantwortliche verlassen können.
Auch beim Einsatz von Best Practice JavaScript SEO Maßnahmen ist keine Garantie für die korrekte Indexierung gewehrleistet. Ein erster Schritt in die richtige Richtung seitens Google, war das Veröffentlichen des Dokumentes „Rendering von Google Search“ und „Dynamic Rendering. Den Großteil der aktuellen Ressourcen zu JavaScript SEO stammt von sehr engagierten SEOs aus der ganzen Welt, die sich diesem Thema widmen.
Nach Erfahrungen und aktuellen Erkenntnissen kann der Einsatz von JavaScript für die Disziplin SEO nicht empfohlen werden. Es gibt zwar Lösungen und Wege JavaScript und SEO unter einen Hut zu bringen, diese Wege und Lösungen sind aber aufwendig, riskant und fehleranfällig und geben nie eine 100% Garantie, ob Google wirklich alles so verarbeitet wie gewollt. Daher gibt es abschließend eine klare Empfehlung für den Einsatz von Prerendering.
Abschließend ein Zitat vom Kollegen Bartosz: „Ranking well with CSR JavaScript Websites is very hard if not impossible“.
Abschließen gibt es hier nochmals die Webinar-Aufzeichnung bei Searchmetrics und die Slides zu Vorträgen von der SEOKomm, dem SEO Day und der SEO Campixx zu JavaScript SEO.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Klicken Sie auf den unteren Button, um den Inhalt von www.slideshare.net zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von www.slideshare.net zu laden.
Klicken Sie auf den unteren Button, um den Inhalt von www.slideshare.net zu laden.