- 25. Februar 2019
- 9 Min
So wirst du von Google als Entität wahrgenommen
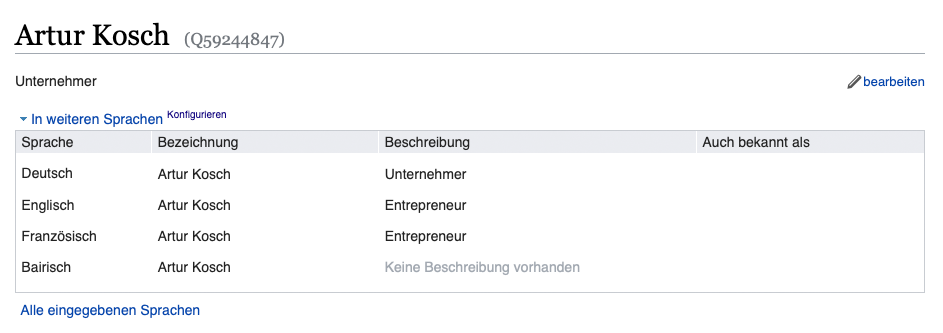
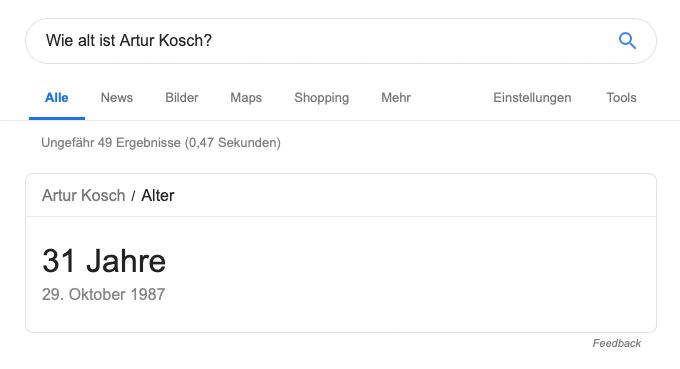
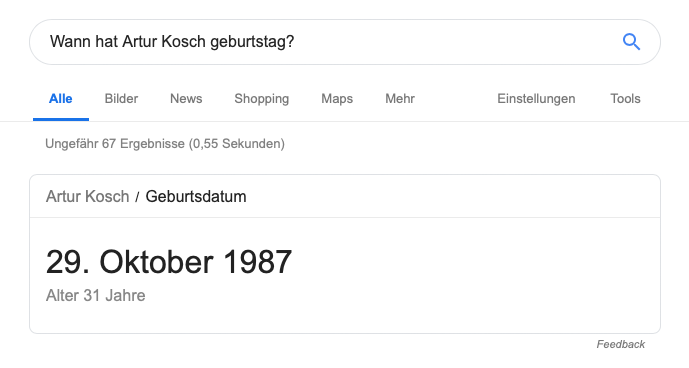
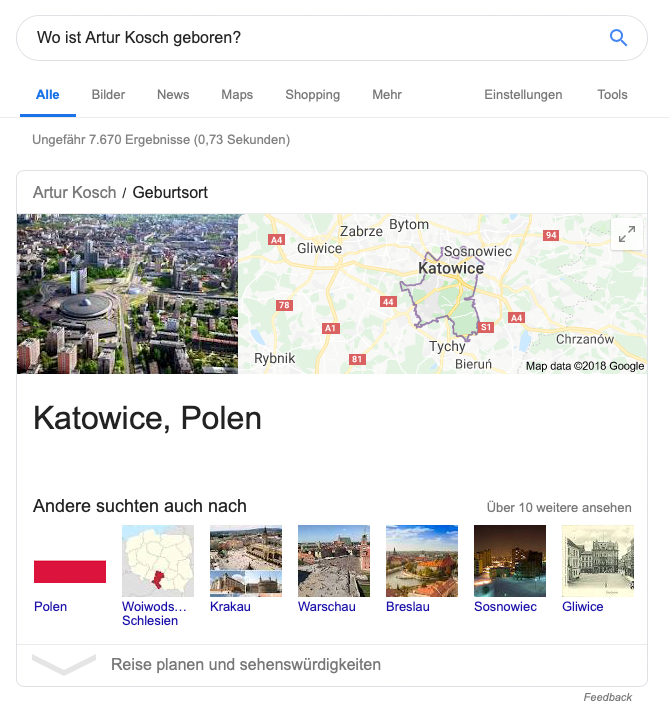
Das Selbstexperiment: in 2 Tagen zur Entität bei Google


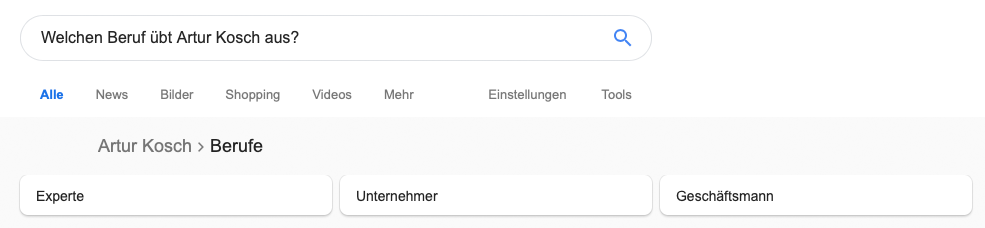
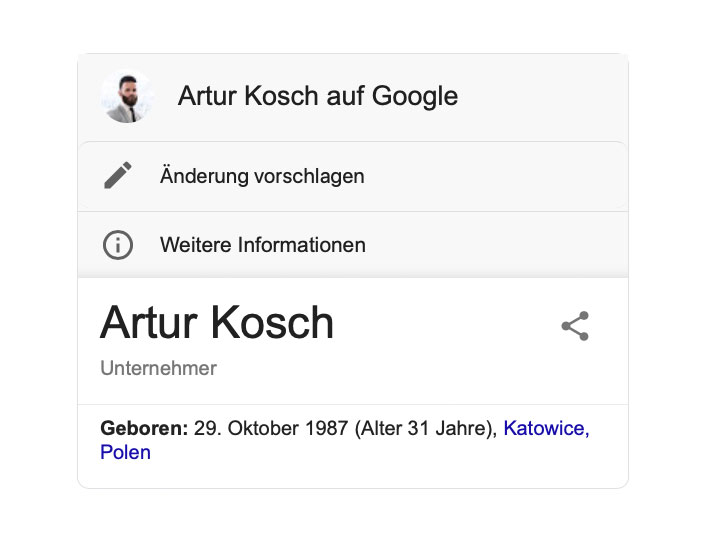


Dein Fundament für nachhaltige Sichtbarkeit in der KI-Suche!

Harmonic Centrality ist eine Metrik aus der Netzwerkanalyse, die aktuell verstärkt im…
SEO wird im Finanzumfeld häufig auf Sichtbarkeit und Reichweite reduziert, doch aktuelle…

Die Diskussion rund um ChatGPT Ads wird aktuell oft auf eine sehr…

Mit der Android-Beta 1.2025.329 ist erstmals ein Leak aufgetaucht, der zeigt: OpenAI…

Die Diskussion rund um KI-Suche ist derzeit stark von Zukunftsprognosen geprägt –…